
Introduction
When beginning the process of creating an AWS environment, there are countless considerations and choices that need to be made. Among these, establishing a consistent and effective naming convention stands out as an often overlooked, yet incredibly important aspect.
Some may question its relevance, but the reality is simple – maintaining an AWS environment can quickly become a complex task. Certain AWS resources are not designed to allow for name changes after they’ve been set, and adjusting the name of interdependent resources can inadvertently lead to unexpected complications.
In this article, we will explore the world of AWS naming conventions, not from the standpoint of an ultimate guide, but as a reflection on the topic. Let’s navigate this path together, shedding light on the seemingly inconspicuous yet crucial aspect of AWS usage – naming conventions.
Why We Need a Naming Convention in AWS
At first glance, it might seem sensible to consider that smaller AWS environments don’t necessarily require stringent naming conventions. With just a handful of resources to manage, and an intimate team that understands the function of each one, why would you need a formalized naming system? Some might argue that the introduction of naming conventions leads to unnecessary complexity or red tape.
True, implementing and adhering to a naming convention demands a level of planning and discipline. Yet, considering the broader picture, it’s a worthy investment due to the potential value that can be reaped from employing a consistent naming strategy.
First of all, it’s important not to underestimate the significance of future growth. AWS environments are inherently scalable; they’re engineered to expand over time to accommodate growing needs. As your environment evolves, establishing a naming convention at a later stage, when you have a larger set of resources to manage, can become a burdensome task. As I’ve highlighted in the introduction, changing the names of existing resources can result in potential technical debt that demands substantial effort to rectify.
Secondly, consistency is the cornerstone of clear communication, particularly in a collaborative environment. Even in smaller teams, a defined naming structure ensures that everyone understands the purpose and role of each resource. This minimizes misunderstandings and miscommunications that could potentially lead to errors.
Tag Feature in AWS is Good, But a Naming Convention Still Matters
As we delve deeper into resource management within AWS, one might wonder if the tagging feature can replace the need for a naming convention. In some cases, this might seem feasible depending on the specific requirements and constraints of your environment. After all, tags offer an excellent level of control over your resources, making governance significantly simpler.
Additionally, AWS furnishes a host of services that make effective use of tags such as AWS Resource Groups and AWS Resource Explorer. And most of these are available at no additional cost, making them a tempting proposition for resource management.

The usage of tags can indeed deliver significant value and ease, surpassing the benefits that a naming convention might offer in some respects. However, there still exist compelling reasons to establish a well-thought-out naming convention.
Firstly, in certain scenarios, utilizing a naming convention can be a simpler approach than relying entirely on tags. This could be the case when dealing with AWS console navigation or when quickly identifying resources is key. Managers and operators accustomed to the AWS console might find it cumbersome to navigate resources through tags.
It’s not just about catering to beginners or less-experienced users, either. Even for seasoned engineers, simplicity and ease of use are critical. No one wants to waste valuable time deciphering tags and resource groupings, regardless of their proficiency with AWS CLI and queries. Intuitive, meaningful names can save time, reduce cognitive load, and make everyone’s job a bit easier.
Secondly, it’s worth noting that not all AWS resources support tags. While AWS has been progressively adding tagging capabilities to more services, there still remain some that don’t support this feature. You can check the status of different services in this link.
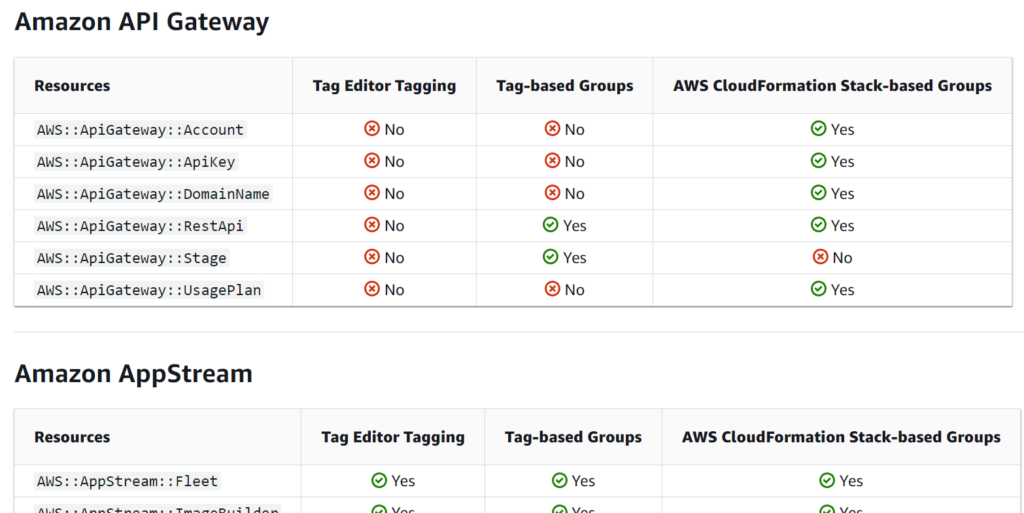
If your resource management strategy relies entirely on tags, encountering a resource that doesn’t support tagging could create unnecessary complications.
Thus, while tags are indeed a powerful tool within AWS, a well-structured naming convention remains an essential element of effective resource management.
What Could Be the Best Naming Convention?
AWS doesn’t provide an official, standardized naming convention, so it falls to us to consider what an effective naming convention might be. The key considerations that come to mind are the format to use and how to organize resource names.
If we’re looking for a universal approach, the most crucial criterion is arguably inclusivity. To that end, let’s examine the naming conventions of major AWS services to identify rules that can accommodate a broad range of AWS resource names. The examples in the table below showcase the naming capabilities supported by different AWS resources. Please bear in mind that this information may contain errors; for definitive information, double-check with official AWS resources.
| AWS Resource | Example | Letter case | Number | Special Characters | Letter Size |
| S3 Bucket | example-s3.bucket | Lower | Yes | – . | 3 – 63 |
| the resources to use tag for setting name (EC2, EBS, AMIs, VPCs ..) | Example-ec2-instance | Upper/Lower | Yes | Unicode chars in UTF-8 | 1 – 128(key), 0 – 256(value) |
| RDS DB identifier | example-rds-instance | Lower | No | – | 1 – 63 |
| Lambda Function | Example-lambda_function | Upper/Lower | Yes | – | 1 – 64 |
| IAM User, Role | Example-user+=,.@_- | Upper/Lower | Yes | + = , . @ _ – | 1 – 64 |
| DynamoDB Table | Example-dynamodb_table | Upper/Lower | Yes | _ – . | 3 – 255 |
| Elastic Load Balancer (ELB, ALB, NLB) | Example-elb | Upper/Lower | Yes | – | 1 – 32 |
| CloudFormation Stack | Example-cfn-stack | Upper/Lower | Yes | – | 1 – 128 |
| Redshift Cluster | example-redshift-cluster | Lower | Yes | – | 1 – 63 |
| SNS Topic | Example-sns_topic | Upper/Lower | Yes | _ – | 1 – 256 |
| SQS Queue | Example-sns_topic | Upper/Lower | Yes | _- | 1 – 80 |
As you can see, naming constraints vary quite a bit across different AWS services, which can be a bit of a hurdle. However, we have to work within these constraints and devise a naming convention that works for most resources. The most notable commonality across most services is that they support lowercase letters and hyphens (-) in their names.
Given these observations, it seems sensible to use kebab-case as our primary naming format. Kebab-case is a style of writing that combines words using hyphens, all in lowercase. An example might be “example-s3-bucket”.
With our format sorted, the next task is to determine how to structure our resource names. This will largely depend on the specifics of your project and how you’re using AWS, but for a generally versatile structure, the following plan might be an option:
- Project Name
- Environment (e.g., dev, staging, prod)
- Region/Location
- Resource Type
- Functional Role: This indicates the role or purpose of the resource. For instance, if it’s a database, you might use “db”. If it’s a web server, you might use “web”.
- Unique Identifier: This could be an incremental number or random string that ensures the name’s uniqueness.
Combining these elements, an example naming convention could look something like this: {project}-{environment}-{region}-{resource-type}-{functional-role}-{unique-identifier}.
So, a typical resource name might appear as “customapp-dev-useast1-ec2-web-001“. Keep in mind, this is just one approach, and your specific requirements and specifications may call for something different. Consider this a flexible blueprint to build upon.
Conclusion
In conclusion, it’s all too easy to overlook the necessity of a robust naming convention when initiating small-scale AWS environments or managing segmented projects. However, the reality underscores a different narrative. Implementing a clear, consistent naming convention from the very outset forms a cornerstone for future scalability and efficiency.
It’s a perspective I believe in and advocate. I hope that this article sparks more discussion and thought about this topic. Regardless of how seemingly minor a detail, the impact of a well-designed naming convention on resource management and operational efficiency in AWS environments can be significant.